Using AI to More Effectively Find, Recruit, and Enroll Eligible Patients in Clinical Trials
 Artificial intelligence (AI) is set to change how we all work. The key to successful AI implementations is having a solid idea of how AI can help. Our team at BEKhealth wanted to explore how natural language processing (NLP) could help researchers find, recruit, and enroll eligible patients more effectively. We wanted a technology that could delve into huge volumes of data from multiple sources, encompassing both structured data like electronic medical records and insurance records, as well as unstructured data like physician notes and handwritten patient diaries. We knew we needed AI models that could accurately decipher data related to core record categories like medical procedures, laboratory tests, medication histories, and past/existing diagnoses. With accurate assessments of these categories, researchers would have much more complete pictures of patient eligibility.
Artificial intelligence (AI) is set to change how we all work. The key to successful AI implementations is having a solid idea of how AI can help. Our team at BEKhealth wanted to explore how natural language processing (NLP) could help researchers find, recruit, and enroll eligible patients more effectively. We wanted a technology that could delve into huge volumes of data from multiple sources, encompassing both structured data like electronic medical records and insurance records, as well as unstructured data like physician notes and handwritten patient diaries. We knew we needed AI models that could accurately decipher data related to core record categories like medical procedures, laboratory tests, medication histories, and past/existing diagnoses. With accurate assessments of these categories, researchers would have much more complete pictures of patient eligibility.
BEKhealth sought to evaluate the capabilities of leading AI solutions for natural language processing (NLP) to determine their suitability for use in clinical trial recruitment. These included Amazon Web Service’s Comprehend Medical (AWS), Google Healthcare Natural Language API (Google), John Snow Lab’s Spark NLP (Spark), and the medspaCy NLP models.
Creating a New Gold Standard in Research-specific AI Accuracy
To begin, BEKhealth deployed each of the solutions to extract information of interest from volumes of labeled unstructured and deidentified patient documents. These documents, combined with digital records from electronic medical records (EMR) databases and patient charts, would allow the team to gauge the performance of the existing NLP tools, providing a foundation for the kinds of AI models the company sought to build.
The clinical team quantitatively evaluated the predictions made by the AWS, Google, Spark, and medspaCy NLP solutions, measuring their ability to accurately identify and codify medical information of interest. The AI predictions were then benchmarked against BEKhealth’s human team’s confirmed records of diagnoses, medications, lab tests, biometric measures, clinical observations, and procedures. This data, corrected and validated by BEKhealth’s team of experts, established a new Gold Standard for accuracy that would serve as a performance target as the team sought to build its own AI solution specifically for clinical trial recruitment. The team at BEKhealth investigated how accurately each of the four solutions identified medical procedures (including surgeries), lab tests, biometric measurements, medications, and diagnoses present in patient histories. Performance was summarized using standard performance metrics, each chosen for its ability to provide insights into different aspects of the solution’s effectiveness:
- Accuracy: The overall correctness of the model, i.e., how often the AI’s predictions match the true outcomes.
- Threat Score: The model’s ability to correctly predict the cases of interest, balancing the importance of hits against false alarms.
- Recall: The number of actual positive cases correctly identified by the model.
- Precision: Number of correct positive identifications made by the model.
- Specificity: The true negative rate, i.e., the proportion of actual negative cases that the model correctly identified.
- F1-Score: A harmonic mean of precision and recall, offering a balance between them.
Surpassing Industry Giants
When benchmarked against the NLP solutions from AWS, Google, Spark, and medspaCy, BEKhealth’s AI demonstrated superior performance, particularly in correctly identifying biometrics, clinical observations, lab tests and procedures—areas where unstructured data poses significant challenges. In medication and diagnosis categories, BEKhealth’s AI continued to lead, showcasing its versatility and precision across different data types.
Procedure Data
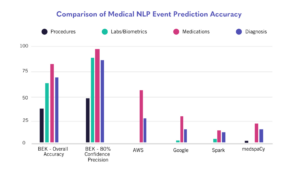
Solution performance for this category was measured based on the ability to accurately identify medical procedures and surgeries from unstructured medical histories and codify those events using standardized medical vocabularies such as the Healthcare Common Procedure Coding System (HCPCS). Performance was poor across all previously existing solutions; AWS, Google, and Spark failed to extract any of the labeled procedures, while the medspaCy model had an accuracy score of 0.5%. BEKhealth scored 37.5% in overall accuracy, and 47.9% when the confidence threshold was set to 0.8.
Lab Data
Solution performance for this category was measured based on the ability to accurately identify biometrics, clinical observations, and lab test measurements and codify those events using the Logical Observation Identifiers, Names, and Codes (LOINC) vocabulary. Performance by the previously existing models was poor on this task as well; AWS failed to identify any of the labeled tests or biometric measures, while the other three solutions all had accuracies under 5%. BEKhealth’s model outperforms the other solutions by wide margins, achieving 61.5% overall accuracy and 87.5% when the confidence threshold is set to 0.8.
Medications
Solution performance for this category was measured based on the ability to accurately identify medication exposures and codify those events using the RxNorm and NDC vocabularies. The medications category saw a significant increase in performance across the board. This appears to be largely attributable to the fact that the classification of medications is more standardized than that of procedures and labs. AWS achieved an accuracy of over 50%, while the other solutions fell in the 15%-30% range. Still, the BEKhealth solution remained the top performer, achieving 79.6% overall medication prediction accuracy and 95.7% when the confidence threshold is set to 0.8.
Diagnoses
Solution performance for this category was measured based on the ability to accurately identify medical conditions and codify those events using the International Classification of Diseases (ICD-10) and the Systematized Nomenclature of Medicine-Clinical Terminology (SNOMED) vocabularies. Again, a high degree of standardization due to robust diagnosis classification systems led to better performance across all NLP models. AWS led the way among previously existing models, falling just above 25% accuracy. BEKhealth’s solution outperformed the others again, leading the way in all diagnostic performance subcategories, with an overall accuracy of 66.8% and 86.1% when the confidence threshold is set to 0.8.
Implications of the Data
The comparison data paints a clear picture of BEKhealth’s AI as an effective solution and, in fact demonstrates that BEKhealth has developed the only solution capable of addressing the unique needs of clinical trial recruitment. Its superior performance across all data categories demonstrates a comprehensive understanding and processing capability that general-purpose NLP tools from AWS, Google, Spark, and medspaCy cannot match. This specialization is particularly important in clinical research, where the accuracy and reliability of data interpretation can directly impact patient outcomes and trial success.
For more information on BEKhealth’s highly accurate AI models and how they facilitate more effective clinical trial recruitment, download our white paper.
Note: Scores out of 100
Read More
The Provenance Gap: Why Real-World Data Passes Technical Review and Fails Regulatory Review
The Provenance Gap: Why Real-World Data Passes Technical Review and Fails Regulatory Review A dataset arrives. The technical review goes well. Field completeness is high. Record counts meet the requirement. The mapping runs cleanly. Everyone signs off. Eighteen months...
What ICH M14 Changes About How Sponsors Choose Real-World Data Sources
What ICH M14 Changes About How Sponsors Choose Real-World Data SourcesReal-world data sourcing used to happen after the protocol was written. A team defined the research question, drafted the design, then went looking for a dataset that could answer it. Procurement...
What Makes Real-World Data “Research-Ready”? A Fitness-for-Use Framework
What Makes Real-World Data "Research-Ready"?: A Fitness-for-Use FrameworkEvery real-world data (RWD) source looks strong on a slide. The patient counts are large. The therapeutic areas are broad. The logos are familiar. On paper, one dataset looks much like another....
Speed, Accuracy, and Trust in Real-World Evidence: A Researcher’s View
Speed, Accuracy, and Trust in Real-World Evidence: A Researcher's ViewReal-world evidence is only as good as the data behind it, and speed, accuracy, and trust are usually treated as trade-offs. A researcher working with the BEKnetwork recently described what it looks...